정의
- 동적 계획법 (DP 라고 많이 부름)
• 입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결,
최종적으로 전체 문제를 해결하는 알고리즘
• 상향식 접근법으로, 가장 최하위 답을 구한 후 저장, 해당 결과 값을 이용해서 상위 문제를 풀어가는 방식
• Memoization 기법을 사용
• Memoization (메모이제이션) 이란?
• 프로그램 실행 시 이전에 계산한 값을 저장하여, 다시 계산하지 않도록 하여 실행 속도를 빠르게 하는 기술
• 문제를 잘게 쪼갤 때, 부분 문제는 중복되어, 재활용됨
• 예 : 피보나치 수열
- 분할 정복
• 문제를 나눌 수 없을 때까지 나누어서 각각을 풀면서 다시 합병하여 문제의 답을 얻는 알고리즘
• 하향식 접근법으로, 상위의 해답을 구하기 위해, 아래로 내려가면서 하위의 해답을 구하는 방식
• 일반적으로 재귀함수로 구현
• 문제를 잘게 쪼갤 때, 부분 문제는 서로 중복되지 않음
• 예 : 병합 정렬, 퀵 정렬 등
공통점과 차이점
- 공통점
• 문제를 잘게 쪼개서, 가장 작은 단위로 분할
- 차이점
• 동적 계획법
• 부분 문제는 중복되어, 상위 문제 해결 시 재활용됨
• Memoization 기법 사용(부분 문제의 답을 저장해서 재활용하는 최적화 기법으로 사용)
• 분할 정복
• 부분 문제로 서로 중복되지 않음
• Memoization 기법 사용 안함
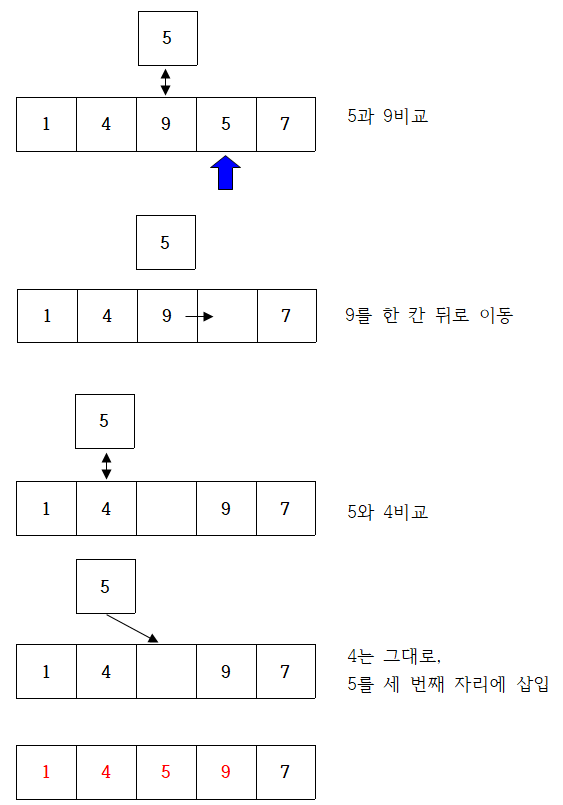
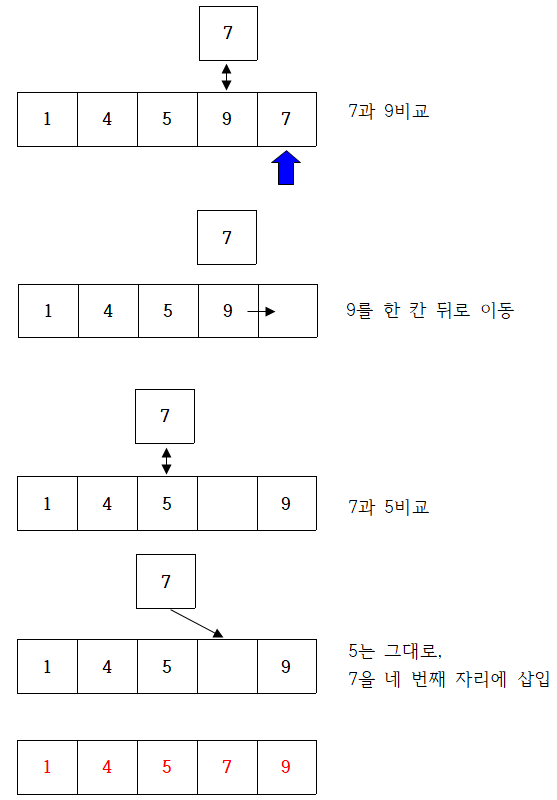
동적 계획법 알고리즘 이해 (피보나치 수열)
- recursive call 활용
def fibonacci(num):
if num <= 1:
return num
return fibonacci(num + 1) + fibonacci(num + 2)
print(fibonacci(10)) # 55
- 동적 계획법 활용
def fibonacci_dp(num):
cache = [index for index in range(num + 1)] # list comprehension
cache[0] = 0
cache[1] = 1
for index in range(2, num + 1):
cache[index] = cache[index - 1] + cache[index - 2]
return cache[num]
print(fibonacci_dp(10)) # 55'Algorithm & Data Structure > Algorithm' 카테고리의 다른 글
| [알고리즘] 재귀 용법 (recursive call) (0) | 2020.06.16 |
|---|---|
| [알고리즘] 선택 정렬 (selection sort) (0) | 2020.06.16 |
| [알고리즘] 삽입 정렬 (insertion sort) (0) | 2020.06.15 |
| [알고리즘] 버블 정렬 (bubble sort) (0) | 2020.06.15 |