링크드 리스트 구조
- 연결 리스트라고도 함
- 배열은 순차적으로 연결된 공간에 데이터를 나열하는 데이터 구조
- 링크드 리스트는 떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조
- 링크드 리스트 기본 구조와 용어
• 노드(Node) : 데이터 저장 단위 (데이터 값, 포인터)로 구성, 하나의 데이터
• 포인터(pointer) : 각 노드 안에서, 다음이나 이전의 노드와의 연결 정보를 가지고 있는 공간
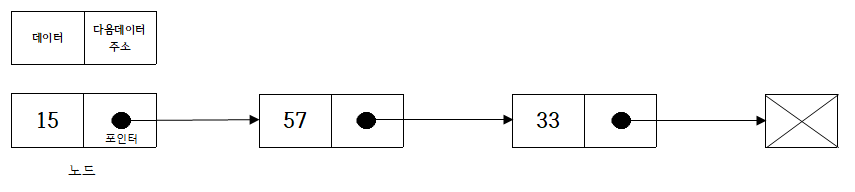 일반적인 링크드 리스트
일반적인 링크드 리스트
링크드 리스트의 장단점
- 장점
• 미리 데이터 공간을 할당하지 않아도 된다. (배열은 미리 데이터 공간을 할당)
- 단점
• 연결을 위한 별도 데이터 공간이 필요하므로, 저장 공간 효율이 높지 않다.
• 연결 정보를 찾는 시간이 필요하므로 접근 속도가 느리다.
• 중간 데이터 삭제 시, 앞뒤 데이터의 연결을 재구성해야 하는 부가적인 작업이 필요하다.
파이썬 객체지향 프로그래밍으로 링크드 리스트 구현 : 노드 생성, 추가, 삭제, 검색
class Node: # 노드 생성
def __init__(self, data):
self.data = data
self.next = None
class NodeMgmt:
def __init__(self, data): # 맨 앞에 값을 지정
self.head = Node(data)
def add(self, data): # 데이터 추가
if self.head == '':
self.head = Node(data)
else:
node = self.head
while node.next:
node = node.next
node.next = Node(data) # 노드 연결
def desc(self): # 해당 전체 링크드 리스트 출력
node = self.head
while node:
print(node.data)
node = node.next
def delete(self, data): # 데이터 삭제
if self.head =='':
print('해당 값을 가진 노드가 없습니다.')
return
if self.head.data == data: # head 삭제
temp = self.head
self.head = self.head.next
del temp
else:
node = self.head
while node.next: # head가 아닌 노드 삭제
if node.next.data == data:
temp = node.next
node.next = node.next.next
del temp
return
else:
node = node.next
def search_node(self, data): # 노드 삭제
node = self.head
while node:
if node.data == data:
return node
else:
node = node.next


