스택
- 데이터를 제한적으로 접근할 수 있는 구조
• 한쪽 끝에서만 자료를 넣거나 뺄 수 있는 구조
- 가장 나중에 쌓은 데이터를 가장 먼저 빼낼 수 있는 데이터 구조
• 큐 : FIFO 정책
• 스택 : LIFO 정책
스택 구조
- 스택은 LIFO(Last In, First Out) 또는 FILO(First In, Last Out) 데이터 관리 방식을 따름
• LIFO : 마지막에 넣은 데이터를 가장 먼저 추출하는 데이터 관리 정책
• FILO : 처음에 넣은 데이터를 가장 마지막에 추출하는 데이터 관리 정책
- 대표적인 스택의 활용
• 컴퓨터 내부의 프로세스 구조의 함수 동작 방식
- 주요 기능
• push() : 데이터를 스택에 넣기
• pop() : 데이터를 스택에서 꺼내기
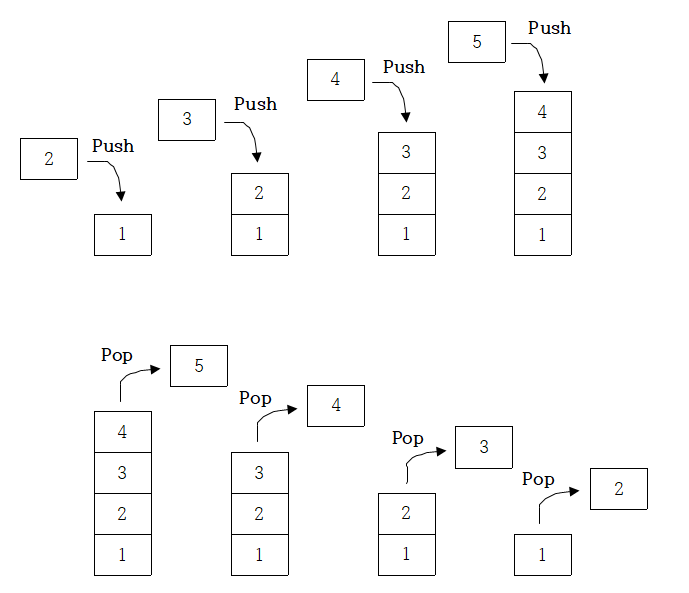
스택 구조와 프로세스 스택
- 장점
• 구조가 단순해서, 구현이 쉽다.
• 데이터 저장/읽기 속도가 빠르다.
- 단점
• 데이터 최대 개수를 미리 정해야 한다.
• 저장 공간의 낭비가 발생할 수 있음
파이썬 리스트 기능에서 제공하는 메서드로 스택 사용해보기
- append(push), pop 메서드 제공
data_stack = list()
data_stack.append(1)
data_stack.append(2)
print(data_stack) # [1, 2]
print(data_stack.pop()) # 2
- pop(), push() 기능 구현해보기
stack_list = list()
def push(data):
stack_list.append(data)
def pop():
data = stack_list[-1]
del stack_list[-1]
return data
for index in range(10):
push(index)
print(pop()) # 9'Algorithm & Data Structure > Data Structure' 카테고리의 다른 글
| [자료구조] 해쉬 테이블 (Hash Table) - 2 (0) | 2020.08.24 |
|---|---|
| [자료구조] 해쉬 테이블 (Hash Table) - 1 (0) | 2020.08.24 |
| [자료구조] 이중 링크드 리스트 (Double Linked List) (0) | 2020.06.30 |
| [자료구조] 링크드 리스트 (Linked List) (2) | 2020.06.24 |
| [자료구조] 큐 (Queue) (0) | 2020.06.17 |
